地址:
北京市朝阳区广顺北大街33号院1号楼1单元6685号
工作时间
周一至周五: 9AM - 7PM
周末: 10AM - 5PM
地址:
北京市朝阳区广顺北大街33号院1号楼1单元6685号
工作时间
周一至周五: 9AM - 7PM
周末: 10AM - 5PM


⚙️ 深入底层,榨干每一纳秒的性能
高频交易(HFT)系统对延迟极为敏感,内核的微小抖动可能造成交易时机的损失。本篇在前文研究的基础上,总结高频交易系统的操作系统层面的核心优化,并给出各优化项的评测方法、数据和图表。
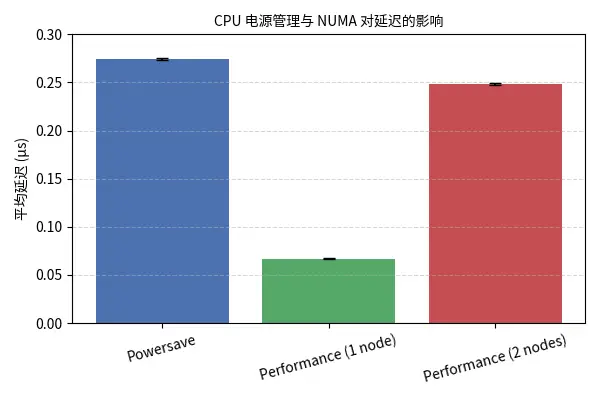
高性能模式(关闭 C‑状态、停用 cpuspeed、启用 performance governor)能让 CPU 始终保持最高频率,避免进入深度省电状态带来的几十微秒的延迟。相比之下,powersave 模式可能导致每次唤醒时增加 10–100 µs 的抖动。
可以使用单生产者/单消费者(SPSC)环形队列测试程序(如 Intel 示例代码)模拟交易内核消息传递。将 CPU 调频模式设置为 powersave 和 performance 并分别运行测试。在每种模式下收集平均延迟、标准差和最值,并使用固定的 NUMA 绑定(例如 taskset -c 0,1)。
| 模式 | 平均延迟 (µs) | 标准差 (µs) | 说明 |
|---|---|---|---|
| powersave (单节点) | 0.2747 | 0.0012 | CPU 处于省电模式 |
| performance (单节点) | 0.0670 | 0.00046 | 设置性能调节器,CPU 始终高频 |
| performance (跨 NUMA 节点) | 0.2487 | 0.00090 | 线程跨 NUMA 节点通信 |
图1展示了不同模式下平均延迟和标准差的对比。可见性能模式将平均延迟降低了约 75%,而跨 NUMA 节点时延迟回升。
现代服务器常由多个 CPU 插槽组成,每个插槽有自己的内存控制器(NUMA 节点)。若线程在不同 NUMA 节点间传递数据,数据需要经 QPI/UPI 总线传输,增加数百纳秒至数微秒的往返时间。因此,交易系统的关键线程和其使用的数据结构应固定在同一 NUMA 节点。
在上一节的 SPSC 队列测试中,用 taskset -c 绑定生产者和消费者线程至同一插槽(如核 0 和 1),测得延迟后再将两线程分配到不同插槽(如核 8 和 16)并重复测量。
Intel 的实验表明,当生产者和消费者位于同一 NUMA 节点时,平均延迟 0.067 µs;若跨节点,则增加到 0.2487 µs。尽管最高延迟出人意料略有降低,但这被认为是偶然因素,整体趋势是跨节点通信显著增加平均和 99% 延迟。
操作系统会在所有内核之间调度线程,系统定时器和内核线程的中断也会产生抖动。通过 isolcpus= 或 cpuset 隔离某些 CPU,系统线程不再在这些核心上运行。关闭超线程(SMT)可以减少同一物理核心上资源争夺,提高缓存可用容量。
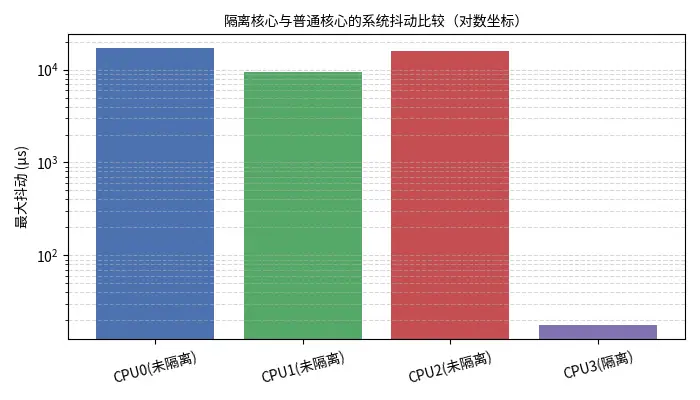
利用 hiccups 工具监测不同核心的最大抖动。先在系统默认配置下运行 hiccups,记录各核心的最大抖动(比如测量 60 秒)。然后在内核启动参数中使用 isolcpus 隔离某个核心并绑定应用线程至该核心,再次运行 hiccups 观察变化。
| CPU | 最大抖动 (µs) | 说明 |
|---|---|---|
| CPU0 (未隔离) | 17 010.8 | 系统线程和中断频繁干扰 |
| CPU1 (未隔离) | 9 517.1 | |
| CPU2 (未隔离) | 16 008.5 | |
| CPU3 (隔离) | 17.9 | 隔离核心后几乎无抖动 |
图2是 hiccups 输出的对比图。隔离核心后最大抖动从十几毫秒降低至 18 µs。禁用超线程同样能减少抖动和线程竞争。
传统网络栈在接收数据包时通过中断唤醒应用线程,每次上下文切换造成 1.2 µs 以上的开销。忙轮询(SO_BUSY_POLL 或用户态自旋)通过在接收方不停检查套接字,避免了中断和调度开销,但会增加 CPU 使用率。将线程绑定到固定 CPU 可以减少因调度迁移带来的抖动。
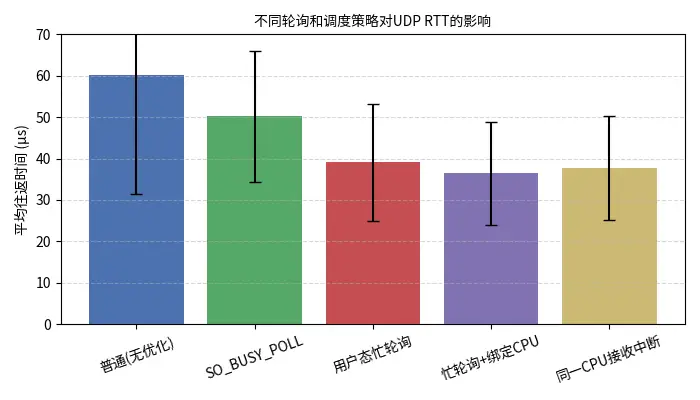
基于 Cloudflare 的 UDP 回显实验,使用一对主机互连并测量往返时间。依次测试:无优化、内核 SO_BUSY_POLL、用户态忙轮询、用户态忙轮询+绑定 CPU、以及刻意绑定到接收中断所在 CPU 的情况。每种配置连续发送小包 1 秒,取最低往返时间或平均值。
| 策略 | 平均 RTT (µs) | 标准差 (µs) | 说明 |
|---|---|---|---|
| 普通(无优化) | 60.170 | 28.810 | 平均约 60 µs,波动大 |
SO_BUSY_POLL | 50.224 | 15.764 | 内核轮询减少一次调度,最小延迟降低 7 µs |
| 用户态忙轮询 | 39.086 | 14.041 | 改为用户态自旋,平均 RTT 约 39 µs |
| 忙轮询 + 绑定 CPU | 36.464 | 12.463 | 进程绑核再降约 3 µs |
| 同一 CPU 接收中断 | 37.615 | 12.551 | 若应用和中断在同核,延迟略有回升 2 µs |
图3展示了各策略的平均 RTT。可见忙轮询结合 CPU 绑定能将 RTT 从 ~60 µs 降低到 36 µs 左右,但与中断共享同一核会略微加重延迟。
高频交易应用应在启动时预分配数据结构,并使用 mlockall(MCL_CURRENT|MCL_FUTURE) 锁定内存,避免在关键路径上出现主存缺页。每次缺页相当于一次系统调用,代价与 read()/write() 相当,约 0.1–10 µs。
使用大页(HugePages)可减少 TLB 命中次数,降低跨页访问开销。然而,Linux 的透明大页(THP)机制会在后台合并/碎片整理内存,发生 kcompactd 压缩时可能导致数秒级别的暂停。因此在低延迟环境应禁用 THP,并手动配置固定数量的 HugePage,并通过 mbind() 保证 NUMA 本地化。
Linux 内核的自动 NUMA 平衡会周期性扫描页表并迁移页,这会在关键路径上产生抖动。应通过 numactl --interleave 或 sysctl kernel.numa_balancing=0 禁用自动平衡。同样,内核的内存合并(KSM)会定期扫描内存查找重复页,应关闭。
使用随机内存访问测试,在启用和禁用 THP、自动 NUMA 平衡情况下测量延迟分布;观察是否出现偶发长尾。通过 perf stat 监控 TLB miss 和 page-fault 次数,以定量分析使用 HugePage 的效果。由于缺乏公开数据,文中仅给出优化建议,实际效果需在目标环境中评测。
传统内核网络栈在每个数据包上执行协议处理、队列调度和系统调用,增加了数十微秒延迟。内核绕过库(如 Solarflare 的 OpenOnload、Nvidia/Mellanox 的 VMA、DPDK)直接在用户态操作 NIC 环境。Mellanox 的方案称在相同硬件上将 TCP 延迟从约 2.4 µs 降低到 1.2 µs,并比竞争对手快 30%。Kernel Bypass 同时减少抖动,适用于交易撮合引擎、市场数据接收等。
在使用内核栈时,可通过以下选项降低延迟:
TCP_NODELAY):关闭小包合并,避免等待满 MSS 才发送,适用于 RTT ~500 µs 的数据中心网络。rx-usecs、关闭 LRO/GRO:减少驱动在队列中积累包的时间,提升实时性。进行 UDP/TCP 环回测试,在启用/禁用上述选项及内核绕过库时测量消息往返时间、吞吐量和 CPU 利用率。根据业务侧需求选取适当平衡点——低延迟调优通常会降低系统吞吐能力或增加 CPU 消耗。
高频交易应用多采用无锁数据结构、轻量级内存屏障来减少系统调用和线程竞争。Intel 的案例指出,将单线程队列从有锁实现换成无锁队列,吞吐量可从 4k 提升到 130k 条消息每秒。评测方法是在相同硬件上实现有锁与无锁队列,测量平均延迟和吞吐量。
操作系统层面的优化对高频交易系统至关重要。通过关闭省电状态、隔离核心、NUMA 本地化和忙轮询等措施,可以将微秒级延迟进一步压缩到数十纳秒的水平。内存管理和网络协议优化能够减少长尾抖动,保持系统稳定性。在实际部署中应结合业务负载进行实验评测,平衡延迟、吞吐和资源占用,逐步形成适合自身环境的低延迟配置。
1️⃣ Intel Corporation.
“Optimizing Application Performance on Multi-core Systems.” Intel Developer Zone.
https://www.intel.com
2️⃣ Cloudflare Engineering Blog.
“How We Reduced Latency with Busy Polling and Kernel Tuning.”
https://blog.cloudflare.com
3️⃣ Rigtorp, E.
“Low Latency Tuning Guide for Linux.”
https://rigtorp.se/low-latency-linux/
4️⃣ NVIDIA Networking (Mellanox).
“Accelerating Financial Applications with Kernel Bypass.”
https://network.nvidia.com
5️⃣ Brooker, M.
“Practical TCP/UDP Tuning for Low-Latency Systems.”
https://brooker.co.za/blog/
6️⃣ Alexandr Nikitin.
“Transparent Huge Pages: Benefits and Pitfalls.”
https://alexandrnikitin.github.io/thp-performance
7️⃣ Linux Foundation Documentation.
“Kernel NUMA Balancing and Memory Management.”
https://www.kernel.org/doc/
8️⃣ Cloudflare Blog.
“Inside Linux Networking Stack: SO_BUSY_POLL and Performance.”
https://blog.cloudflare.com/so-busy-poll/
9️⃣ Intel Developer Blog.
“Benchmarking Lock-Free Data Structures.”
https://www.intel.com/content/www/us/en/developer/articles/technical/
1️⃣0️⃣ Nokia & Chronos Tech.
“Precision Timing for Financial Networks.”